
Chapter 6
Learning as the Core Output
What do we believe that we haven’t really tested yet? What’s the smallest experiment we could run to learn the most about that belief?
Up to now, the playbook has helped you choose where to focus (strategy), understand customers and systems (discovery), and design products, processes, and development flow (Chapter 5). Chapter 6 is about proving what works and learning from what doesn’t before the stakes get too high — and then feeding that learning back into your system.
In LPPD, validation is not a single test at the end. It is a series of deliberate experiments woven through the development value stream. Each experiment is designed to reduce specific uncertainties about customers, technology, flow, or economics. The goal is to make decisions based on evidence, not optimism or politics.
This chapter collects plays for planning and running those experiments: from early pretotypes and simple prototypes, through integrated tests and pilots, to post-launch learning loops. You’ll see how to use a prototyping ladder, how to define knowledge-based milestones instead of just dates, and how to validate product, process, and business assumptions together.
Section 6.1
Designing Experiments Across the Development Stream
Validation in LPPD means designing a sequence of experiments that track your value stream — not running one big test at the end. Each experiment should be tied to a specific uncertainty and a clear decision it will inform.
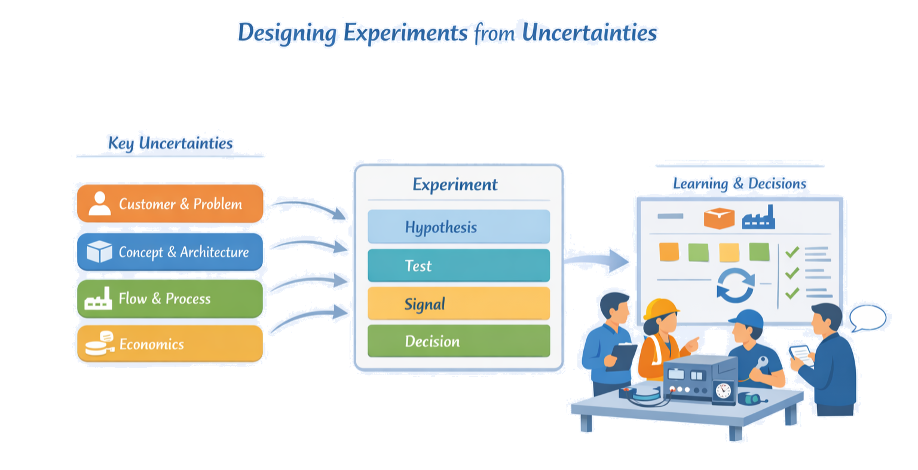
Start from Uncertainties, Not from Methods
Instead of asking “What prototype can we build?”, start with: “What do we not know yet that could really hurt us?”
Are we solving something important for the right people?
Will this concept work in the real context and at scale?
Can we build, test, and deliver this reliably with our system?
Does the combination of value, cost, and risk make sense?
For each cluster, write short uncertainty statements (e.g., “We don’t know if X will adopt this at price Y”, “We don’t know if this interface can handle Z variation”). Those become the backbone of your experiment plan.
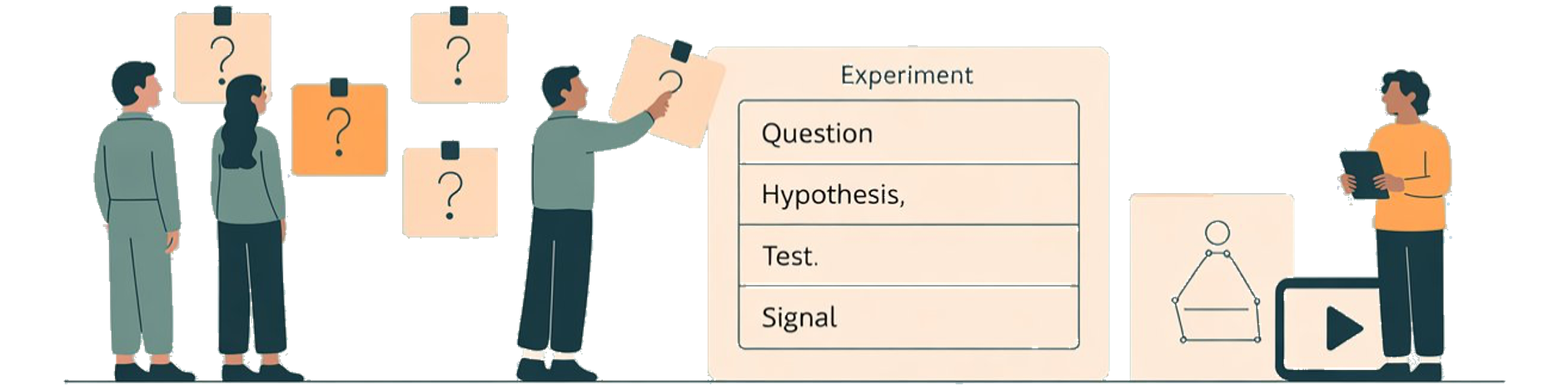
Experiment Pattern: Hypothesis → Test → Signal → Decision
Use a simple, repeatable pattern for every experiment. If you can’t write the Decision part, the experiment is probably not worth running yet.
What you believe, linked to an uncertainty
What you will do to probe it (pretotype, sim, prototype, pilot…)
The observable result if the hypothesis holds
What you will decide or change based on the signal
Spreading Experiments Along the Value Stream
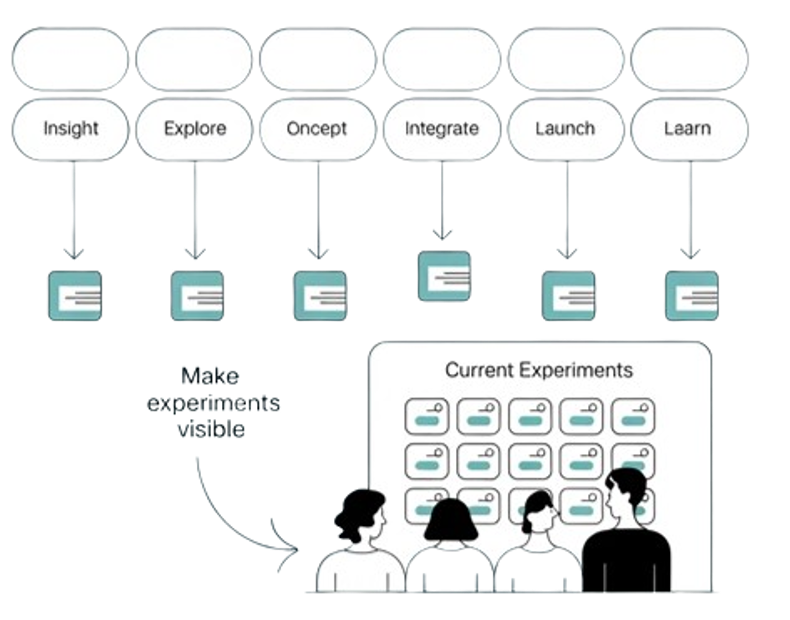
Map experiments across the same stages you used in 5.3. Aim for many small experiments instead of a few huge ones — faster feedback, less risk, more options.
- Insight & framing — Interviews, gemba, problem framing workshops, early pretotype brochures
- Explore & pretotype — Brochure tests, fake-door offers, rough mock-ups, concept comparisons
- Concept & architecture — System simulations, trade-off studies, architecture spikes, set-based evaluations
- Detailed design & process development — Component tests, process trials, DOE, assembly and service try-outs
- Integrate & test — Integration events with combined hardware/software/process, full flow tests
- Launch & ramp-up — Limited launches, pilots with selected customers, phased volume increases
- Learn & improve — Post-launch reviews, field data analysis, experiments on updates and next-gen ideas
Section 6.2
Prototyping Ladder — From Pretotypes to Pilots
For physical products, you can’t afford to build “the whole thing” every time you want to learn something. The prototyping ladder is a series of increasingly realistic ways to test assumptions about product, process, and usage. Each step adds fidelity and cost, but also richer learning. The aim is to climb only as high as you need for the decision at hand.
The Six Rungs

Pretotypes — Paper & Brochure
Representations of the offer without a working product: sales brochures, mock web pages, “coming soon” signs, simple mock-ups.
“Do they care?” • “Can they understand the promise?” • “Who raises their hand?”
Concept & Form Models — Looks Like
Foam models, 3D prints, cardboard rigs, rough enclosures — often non-functional. Explores ergonomics, size, interfaces, and perception of quality.
“Does it fit in their space?” • “Can they handle it easily?” • “Can we assemble / service it?”
Functional Rigs & Breadboards — Works Like
Lab set-ups, bench rigs, breadboards, and hacked-together assemblies that perform key functions but don’t look like the final product.
“Can we achieve these performance targets?” • “Where are the failure modes?”
Alpha Prototypes — Integrated but Rough
Early integrated units that both look and work “close enough” but may be fragile, hand-built, or instrumented. Tests integrated behaviour and key edge cases.
“What happens when everything is bolted together?” • “Where does it fail in realistic use?”
Beta Prototypes / Pre-Series — Production Intent
Units built with near-final parts, processes, and tooling (or close approximations). Validates manufacturability, assembly flow, and early field use in limited numbers.
“Can we build this reliably at a reasonable takt?” • “How does it behave in real customer environments?”
Pilots & Controlled Launches
Limited deployment in real environments with monitored support. Validates the full product + process + service system, economics, and ramp-up assumptions.
“Can we run this as a business?” • “What breaks when we scale from 10 to 100 to 1 000?”
Choosing the Right Rung for the Question
- Customer desirability & positioning — stay on the bottom rungs (pretotype, form model) as long as possible
- Technical feasibility & performance — move into rigs, breadboards, and alpha prototypes
- Flow, manufacturability, and reliability — use beta / pre-series units and pilots
Integrating Process and Production Learning on the Ladder
For physical products, the ladder should always include process learning, not just product learning. Each rung also climbs the ladder for designing the value stream, not only the physical object.
- On concept and form models — check assembly motions, access for tools, and fixture concepts
- On functional rigs — explore test strategies and measurement points, not only performance
- On alpha and beta prototypes — try building using realistic work instructions, fixtures, and test sequences; track build times, issues, and rework
- During pilots — treat the production line and service process as part of the prototype; measure flow, quality, and problem-solving speed
Section 6.3
Knowledge-Based Milestones & Decision Points
In a knowledge-based system, milestones are not calendar dates or document gates. They are decision points where the team pauses to ask: “Do we truly know enough to commit to the next step?” Each milestone is defined by the questions it must answer and the evidence it requires, so decisions flow from learning rather than optimism or politics.
Rungs on the Knowledge Ladder
Think of milestones as a knowledge ladder: a series of decision points where each rung requires a different level of understanding about customer, product, process, and economics. Climb only as high as you need for the commitments at hand.
Problem & Opportunity Clarity
Align on customers, use cases, and value gaps before locking into concepts.
“Whose problem is this?” • “Why now?” • “How will we recognize success?”
Customer & Usage Insight
Turn assumptions about users and usage into grounded insights through interviews, gemba visits, and light experiments.
“How do they work today?” • “What jobs are we actually hired for?” • “What constraints matter most?”
Concept & Architecture Confidence
Decide which sets of concepts to carry forward and which to drop, supported by trade-off curves, simple models, and early tests.
“Which concepts dominate on key trade-offs?” • “What spaces are we keeping open?”
Product & Process Feasibility
Consider product and process together: performance, manufacturability, service, supply, and risk. Decide whether the combination can realistically deliver targets.
“Can we make and service this repeatedly?” • “What is our mitigation plan for the biggest risks?”
Value Stream & Business Viability
Confirm that the emerging solution can win in its market and be sustained by a healthy value stream — product, process, and business model together.
“Can we reach target cost and margin?” • “Where are the economic tipping points?”
Launch Readiness & Learning Capture
Evaluate launch readiness and captured learning after pilots and controlled releases. Decide how to launch, how fast to ramp, and what knowledge to standardize.
“What have pilots taught us?” • “What failure modes remain?” • “What knowledge must we capture now for reuse?”
Integrating Experiments into Milestones
In a knowledge-based system, experiments are how you climb the rungs. Instead of scheduling reviews first and then scrambling for slides, teams work backwards from the knowledge needed at a decision point and design experiments to generate it.
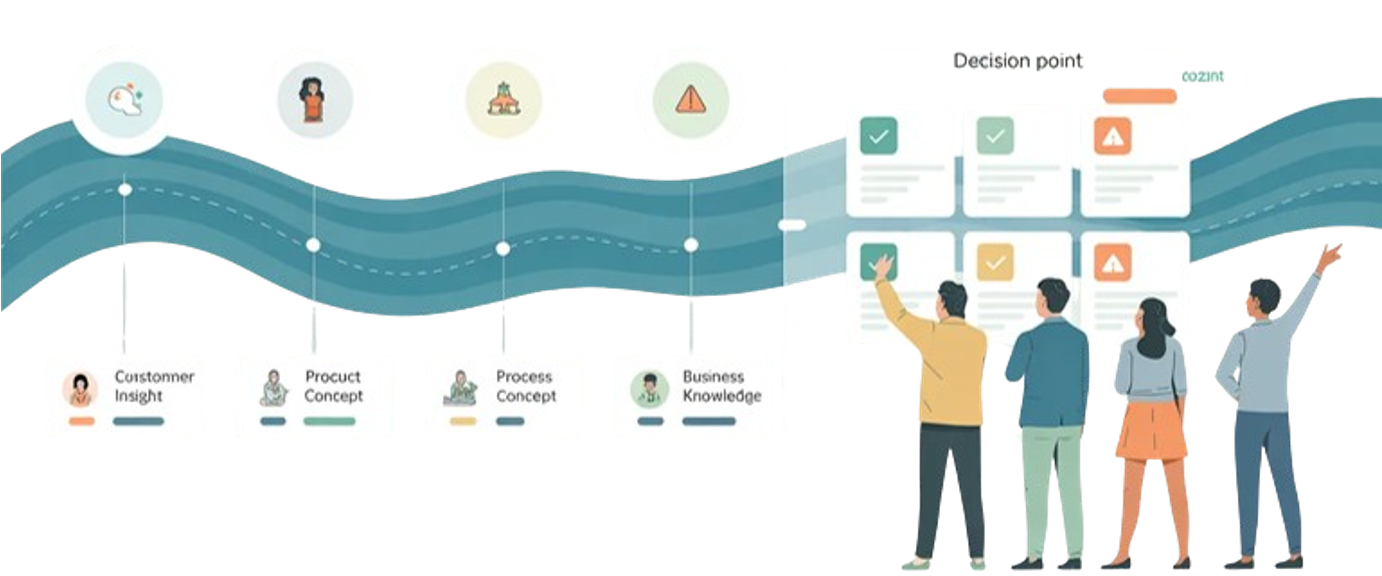
- Before a Concept & Architecture milestone — run experiments that sharpen trade-offs and eliminate weak concepts
- Before a Product & Process Feasibility milestone — test critical interfaces, flows, and failure modes in both product and process
- Before Launch Readiness — use pilots and controlled releases to validate system behaviour, economics, and support
This keeps milestones grounded in evidence on the table, not opinions in the room.
Section 6.4
Validating Product + Process + Business Together
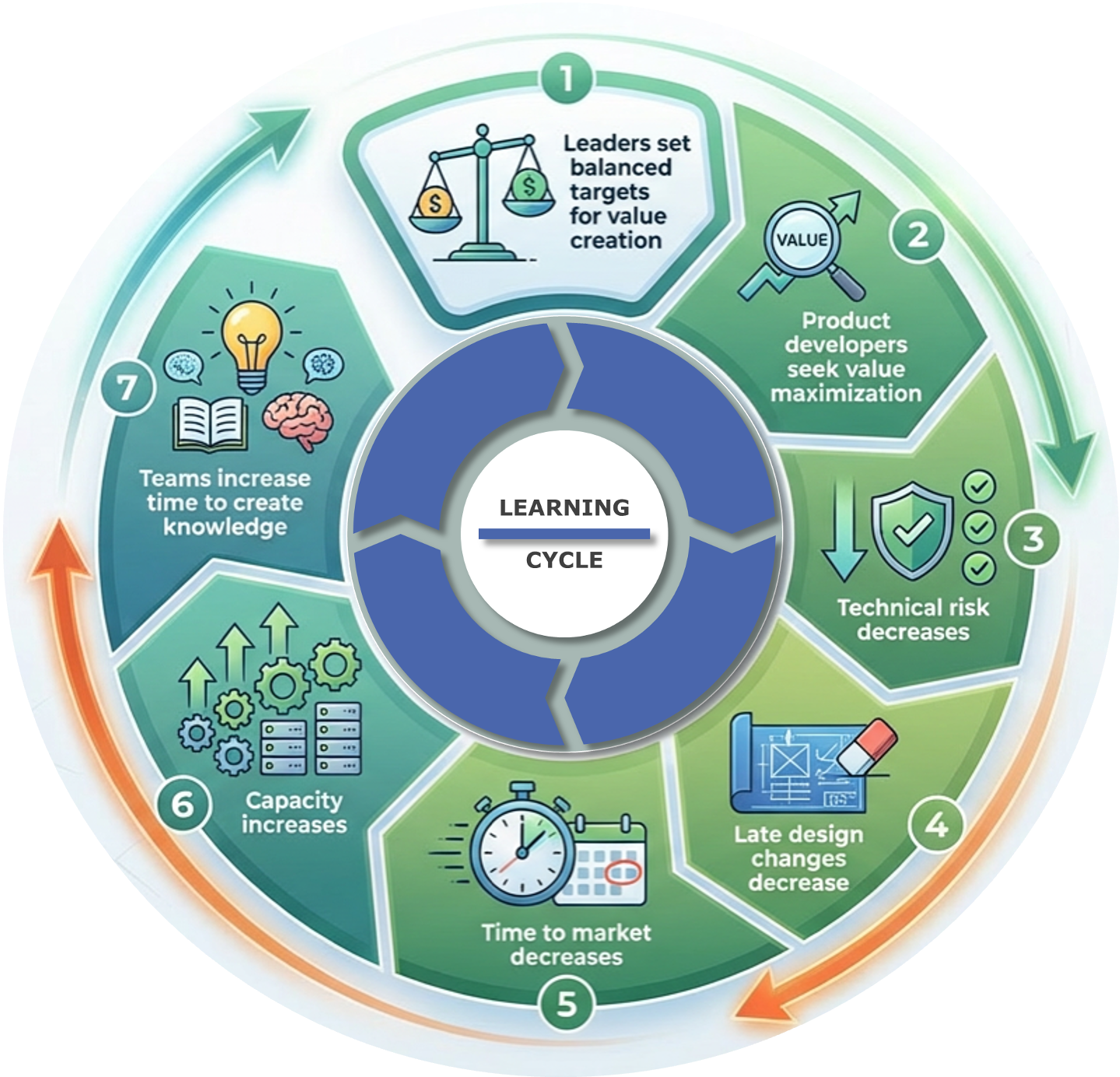
Learning cycles are short, focused loops of experimentation that generate the knowledge needed for upcoming decisions — instead of hoping that learning “just happens” along the way. They bring scientific thinking, cadence, and discipline to how teams design, run, and absorb experiments so that milestones are truly knowledge-based.
What Is a Learning Cycle?
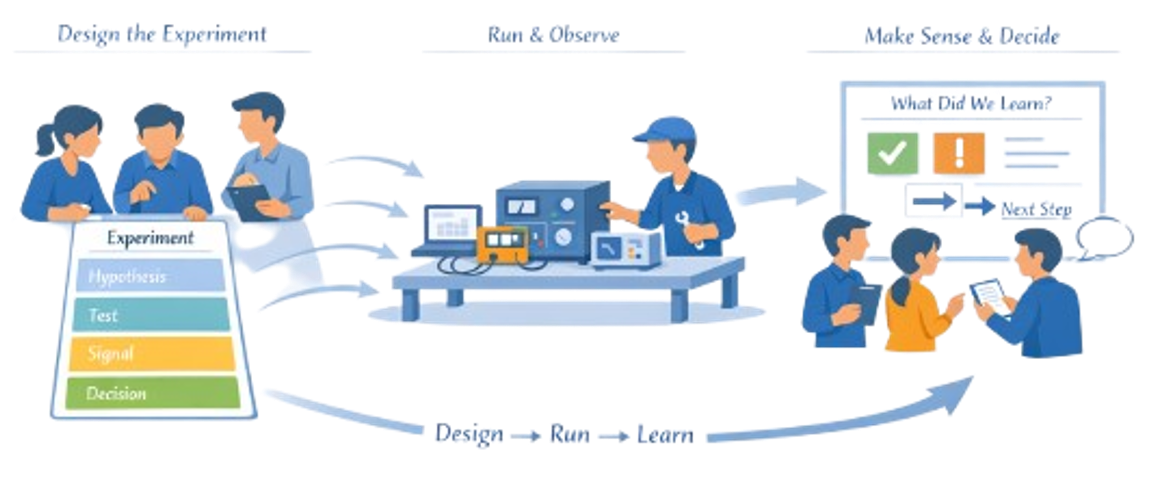
A learning cycle is a time-boxed sequence of activities that turns questions into experiments, evidence, and decisions, then feeds directly into the next cycle.
Designing a Good Learning Cycle
Strong learning cycles are sharp and small: they tackle a narrow uncertainty and produce evidence that someone will actually use. Before launching a cycle, align the team on the following checklist.
- Problem statement: What are we trying to learn or decide?
- Hypotheses: What do we think is true?
- Experiments: How will we test that?
- Success signals: What result would increase our confidence?
- Timebox: How long do we give ourselves before we must look at the evidence?
Running the Cycle
Execution is about rhythm and focus, not heroics. The review is not a status meeting; it is a learning and decision event.
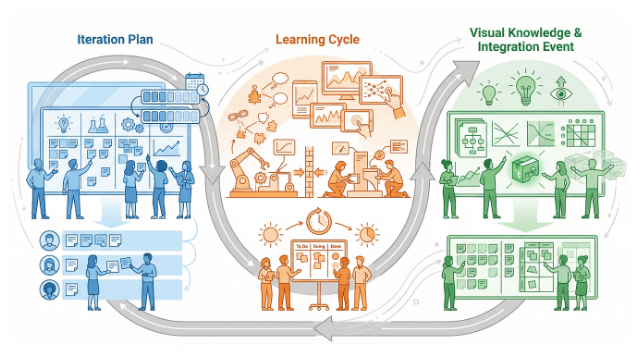
The team brings experiment outputs, discusses what they mean, then compares results to expectations and hypotheses (“what surprised us?”), decides whether to persevere, pivot, or stop, and captures key knowledge in simple, reusable formats so future teams do not have to re-learn the same thing.
This is where learning connects back to knowledge-based milestones: each cycle feeds or updates the evidence for an upcoming decision point.
Section 6.5
Learning After Launch
Launch is not the finish line; it is the moment where reality starts talking back at full volume.
Post-launch, the job of development shifts from “get it out” to “learn fast enough from real use that the next bets are smarter, faster, and less risky.” Before launch, most learning comes from simulations, prototypes, pilots, and controlled environments. After launch, the product lives in messy, varied, real-world conditions with many more users and use cases than any test could cover.
Building Intentional Feedback Loops
Learning after launch is not “collect all the feedback and see what happens”. It is intentional loops that tie signals back to decisions and future development. Think in three layers:
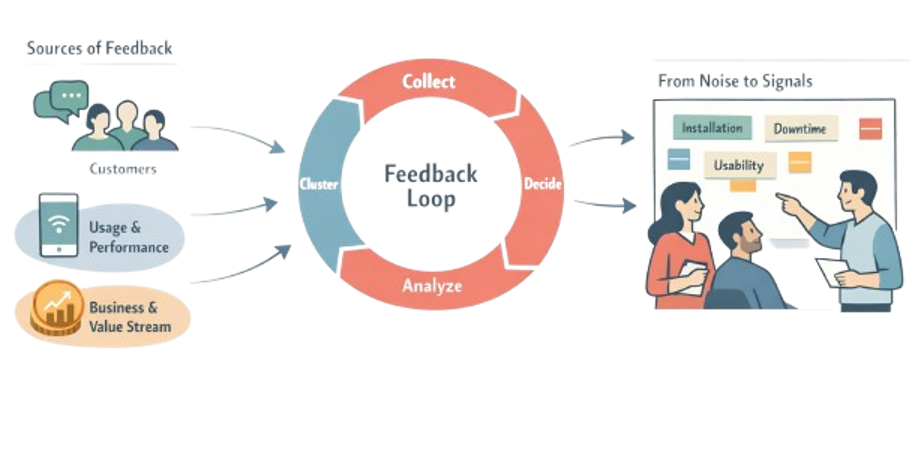
Customer Signals
NPS comments, interviews, field visits, user journeys, complaints, lost deals
Usage & Performance Data
Telemetry, uptime, error codes, cycle times, energy use, maintenance events
Business & Value Stream Outcomes
Margins, service costs, scrap, warranty, lead times, capacity constraints
For each layer, define: what do we want to learn, where will the data come from, and who looks at it regularly — and what decisions does it drive?
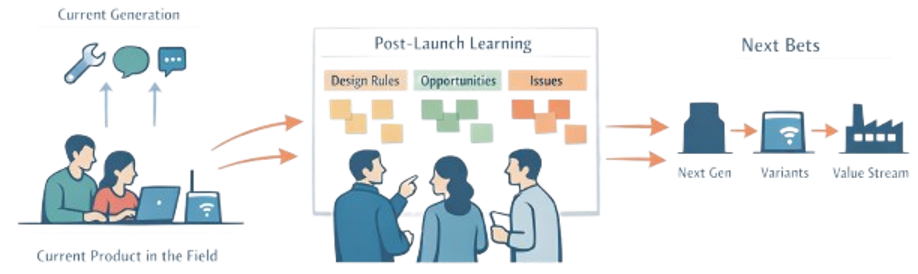
Turning Feedback into Learning, Not Noise
Raw feedback is often contradictory and overwhelming. LPPD treats it as input to structured problem-solving, not a backlog of requests.
- Cluster signals into themes and problems, not feature wishes (“hard to install”, “downtime in dirty environments”, “confusing setup flow”)
- Go to see (gemba) in the field and in service/production to understand context behind the data
- Use lightweight A3s and learning cycles to dig into recurring issues and opportunities, just as you would earlier in development
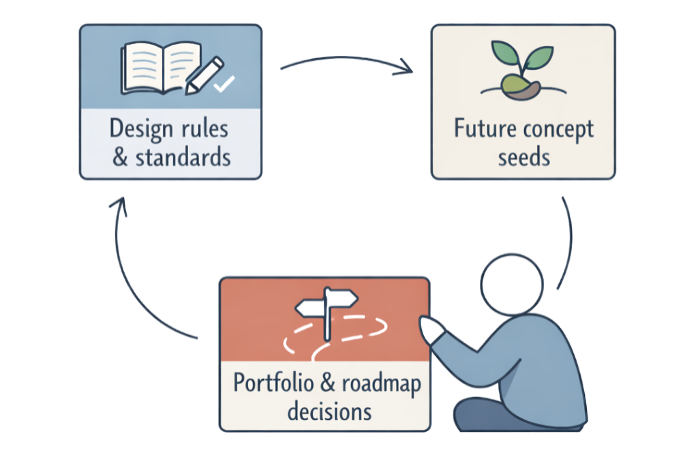
Feeding Learning into the Next Bets
Post-launch learning earns its keep when it shapes next-generation products, variants, and value stream improvements.
- Design rules and standards — Capture robust patterns from the field so future projects start smarter (“never use connector X in outdoor environments”)
- Future concept seeds — Treat strong recurring needs or workaround patterns as seeds for next-gen concepts, not just patches
- Portfolio and roadmap decisions — Use real usage and economics to decide where to invest: which segments to deepen, which features to retire, which platforms to evolve
What did this launch teach us about our customers, our technology, and our value stream — and how does that change our top 3 bets for the next 2–3 years?
Companion Articles